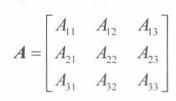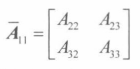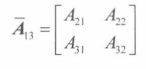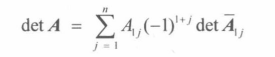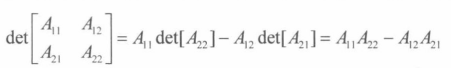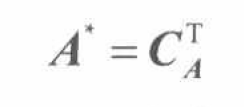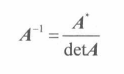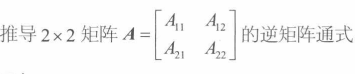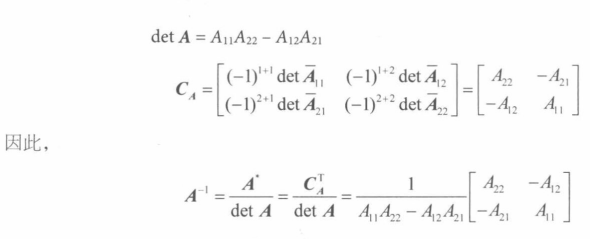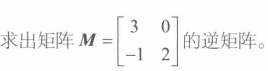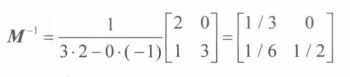简单的自定义视图和节点
本文描述了如何简单的创建自定义的视图和节点
后续补充具体功能开发
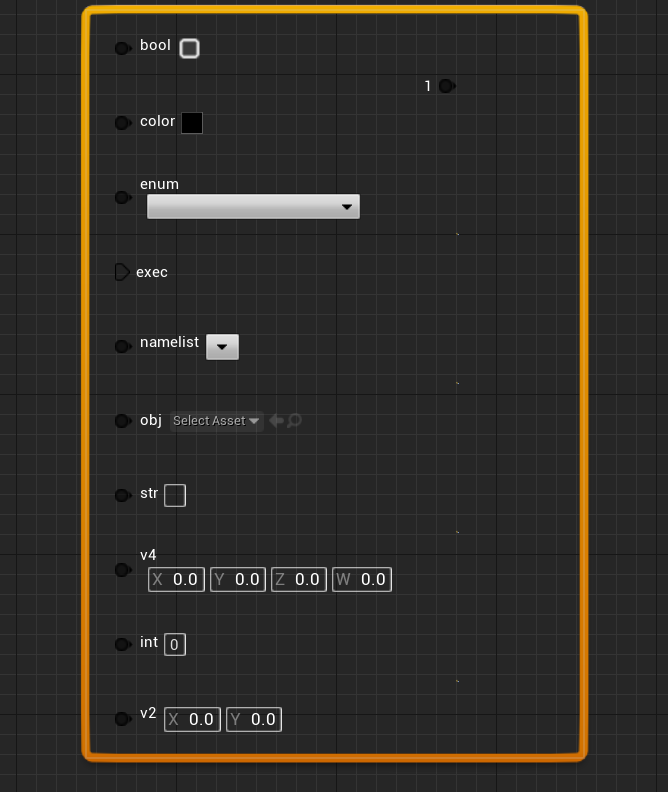
插件模块
创建插件TestGraph
- 包含如下模块
1 | "Projects", |
在模块类里声明2个变量
1 | class UEdGraph* GraphObj;//图表实例的类型,定义了该图表的行为(例如保存图表 |
构造GraphObj,指定GraphObj内的Schema
创建GraphEdSlate,同时把GraphObj指定给GraphEdSlate
1 | GraphObj=NewObject<UEdGraph>(); |
在返回中添加次Slate类
1 | return SNew(SDockTab) |
Schema
EdGraphSchema里定义了图表操作的大部分全局行为- 在
FBlueprintEditorUtils::CreateNewGraph中将UEdGraph和EdGraphSchema建立映射 FEdGraphSchemaAction类主要执行了一个PerformAction,用于生成UEdGraphNode
FEdGraphSchemaAction
- PerformAction
生成节点
1 | UEdGraphNode* FTestGraphSchemaAction::PerformAction(class UEdGraph* ParentGraph, UEdGraphPin* FromPin, const FVector2D Location, bool bSelectNewNode /* = true */) |
UEdGraphSchema
- GetGraphContextActions
右键点击空白页面,用于创建选择节点
1 | void UTestGraphSchema::GetGraphContextActions(FGraphContextMenuBuilder& ContextMenuBuilder) const |
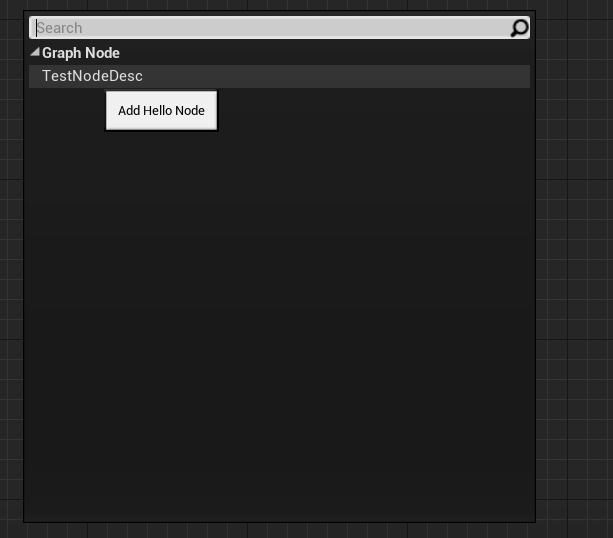
如上图,显示3个对应的名称
- GetContextMenuActions
右键点击节点后的效果,产生例如BreakLink之类的效果
此方法在4.24版本(不确定之前哪个版本开始)有更改如下
2
void GetContextMenuActions(const UEdGraph* CurrentGraph, const UEdGraphNode* InGraphNode, const UEdGraphPin* InGraphPin, class FMenuBuilder* MenuBuilder, bool bIsDebugging) const; //旧版本
1 | void UTestGraphSchema::GetContextMenuActions(class UToolMenu* Menu, class UGraphNodeContextMenuContext* Context) const |
连接方式
1 | UENUM() |
重写CanCreateConnection设置节点的连接方式
1 | virtual const FPinConnectionResponse CanCreateConnection(const UEdGraphPin* A, const UEdGraphPin* B) const |
- 创建连接方式
使用自定义的类FTestConnectionDrawingPolicy来定义连接方式
1 | class FConnectionDrawingPolicy* UTestGraphSchema::CreateConnectionDrawingPolicy(int32 InBackLayerID, int32 InFrontLayerID, float InZoomFactor, const FSlateRect& InClippingRect, class FSlateWindowElementList& InDrawElements, class UEdGraph* InGraphObj) const |
自定义节点
UEdGraphNode
EdGraphNode是图表节点实例的类型,定义了节点的行为AutowireNewNode定义了节点的自动连接行为( 参考上述在schema创建的时候调用)
class UTestNode_Hello :public UEdGraphNode
重写2个方法
AllocateDefaultPins:用于创建节点
GetNodeTitle:标题
可以参考系统的节点
目录大多在
\Engine\Source\Editor\GraphEditor\Public\KismetPins\
1 | void UTestNode_Hello::AllocateDefaultPins() |
SGraphNode
此类是用于显示具体效果的
1 | void Construct(const FArguments& InArgs, UEdGraphNode* InNode);//构造跟默认slate不一样 |
- 构造
1 | GraphNode= InNode;//自带的变量,存储对应的UEdGraphNode |
- 刷新节点
1 | void STestNode::UpdateGraphNode() |
- 创建Pin的图形
2种方式,可以手动指定Pin,也可以使用系统的Pin
1 | //手动指定所有Pin |
1 | //使用系统的Pin |
- AddPin
用来设置Pin的显示和布局
如果不重写,就使用系统自带的Pin(非常的小)
1 | void STestNode::AddPin(const TSharedRef<SGraphPin>& PinToAdd) |
自定义连线
继承自FConnectionDrawingPolicy
- 构造函数
1 | //.h |
- 设置样式
1 | void FTestConnectionDrawingPolicy::DetermineWiringStyle(UEdGraphPin* OutputPin, UEdGraphPin* InputPin, /*inout*/ FConnectionParams& Params) |
- 绘制连接
如果不重写就使用默认的贝塞尔曲线
1 | //绘制直线+流动的泡泡 |
工厂类
可以用工厂类来注册Node,Pin,ConnectionPolicy
重写如下方法
1 | virtual TSharedPtr<class SGraphNode> CreateNode(class UEdGraphNode* Node) const { return NULL; } |
1 | TSharedPtr<class SGraphNode> FTestNodeFactory::CreateNode(class UEdGraphNode* Node) const |
然后在模块加载的时候注册,这样就可以去掉在schema内的内容
1 | FEdGraphUtilities::RegisterVisualNodeFactory(MakeShareable(new FTestNodeFactory)); |
1 | //virtual class FConnectionDrawingPolicy* CreateConnectionDrawingPolicy(int32 InBackLayerID, int32 InFrontLayerID, float InZoomFactor, const FSlateRect& InClippingRect, class FSlateWindowElementList& InDrawElements, class UEdGraph* InGraphObj)const override; |



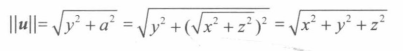
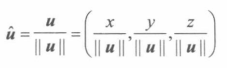
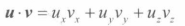

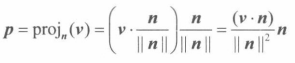
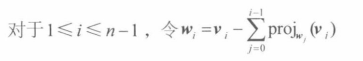
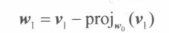
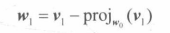
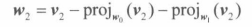
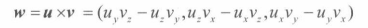







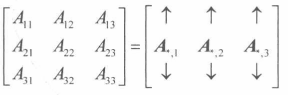
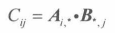
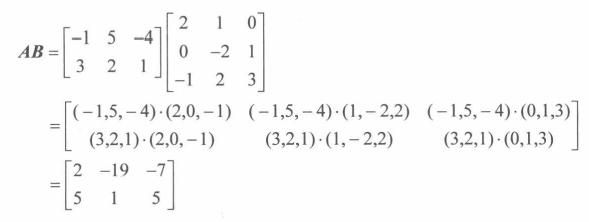
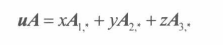
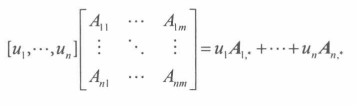
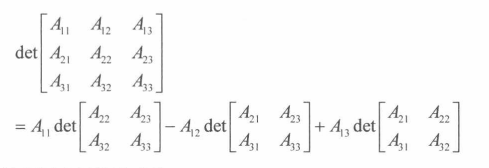
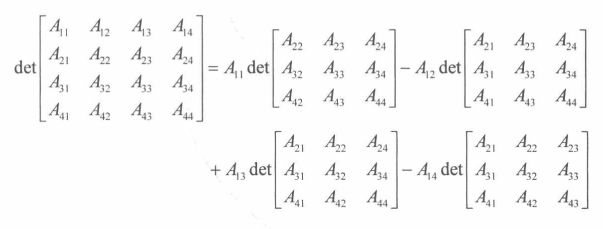
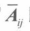 即从A中去除第 i 行和第 j 列的**(n-1)*(n-1)**矩阵
即从A中去除第 i 行和第 j 列的**(n-1)*(n-1)**矩阵